
Elasticsearch: 基于Text Embedding的文本相似性搜索

本文探讨了Text Embedding和ElasticSearch的向量类型如何用于支持文本相似性搜索。本文将首先概述Text embedding技术,介绍该技术的一些应用场景,最后使用ElasticSearch完成一个简单的基于Text embedding的文本相似性搜索demo。
从一开始Elasticsearch就作为全文搜索引擎提供快速而强大的全文搜索功能。在Elasticsearch 7.0中,ES引入了高维向量的字段类型,现在7.3版本支持在文档评分中使用这些向量。
相似性搜索的一个简单方法是根据文档与查询共享的单词数对文档进行排名。但是文档可能与查询类似,即使它们没有太多共同的单词——更强大的相似性概念也会考虑到它的语法和语义内容。
自然语言处理(NLP)社区开发了一种称为文本嵌入的技术,它将单词和句子编码为数字向量。这些向量表示被设计用来捕获文本的语言内容,并且可以用来评估查询和文档之间的相似性。
什么是词向量
Word embeddings 词嵌入
单词嵌入模型将单词表示为密集数字向量。这些向量旨在捕获单词的语义属性 - 向量靠近在一起的单词在语义上应该是相似的。在一个训练较好的embedding中,向量空间中的方向与单词意义的不同方面相关联。例如,“加拿大”的向量可能在一个方向上接近“法国”,而在另一个方向上接近“多伦多”。
一段时间以来,自然语言处理(NLP)和搜索社区一直对单词的向量表示感兴趣。在过去的几年中,人们对单词嵌入的兴趣再次兴起,当时许多传统的任务正在使用神经网络进行重新审视。开发了一些成功的Word embedding算法,包括word2vec和GloVe,还有后来的训练速度更快的Fasttext。这些方法使用大型文本集合,并检查每个单词出现的上下文以确定其向量表示:
- word2vec:Skip-gram模型训练神经网络以预测句子中单词周围的上下文单词。
- GloVe:单词的相似性取决于它们与其他上下文单词出现的频率。该算法训练单词共现计数的简单线性模型。
- Fasttext:Facebook的词向量模型,其训练速度比word2vec的训练速度更快,效果又不丢失。
许多研究小组分发的模型已在大型文本语料库(如维基百科)上进行了预训练,使其便于下载和插入下游任务。尽管经常使用预训练版本,但调整模型以适应特定目标数据集和任务会很有帮助。这通常通过在预训练模型上运行轻量级微调步骤来实现。
Word embedding已被证明非常强大和有效,现在NLP任务(如机器翻译和情感分类)中使用Word embedding已经越来越多。
Sentence embeddings 句子嵌入
最近,研究人员不仅关注单词级别的Word embedding,而且开始关注较长的文本如何进行词向量表示。当前大多数的方法基于复杂的神经网络架构,并且有时在训练期间需要不断标记数据以帮助捕获语义信息和提高训练效果。
一旦经过训练,模型就能够获取一个句子并为上下文中的每个单词生成一个向量,以及整个句子的向量。与嵌入字词类似,许多模型的预训练版本可用,允许用户跳过昂贵的培训过程。虽然训练过程可能非常耗费资源,但调用模型的重量要轻得多。训练好的Sentence embeddings足够快,可以用作实时应用程序的一部分。
一些常见的句子嵌入技术包括InferSent,Universal Sentence Encoder,ELMo和BERT。改进单词和句子嵌入是一个活跃的研究领域,并且可能会引入更多强大的模型。
与传统搜索方法的比较
在传统的信息检索中,我们基于大多使用TF-IDF等基于单词个数的搜索方法,我们只是计算单词出现而不考虑句子结构。而基于text embedding等技术的搜索,将会考虑句子意思。比如“上午吃饭吗”和“我eat早餐了”这两个句子没有一个单词一样,但是其语义是完全接近的,使用text embedding将能够很好的搜索出来。
文本嵌入在某些重要方面与传统的矢量表示不同:
- Text embedding的向量通常纬度比较低,100~1000。而传统的words vectors纬度可以到5000+。Text embedding技术将文本编码为低维空间向量,同义词和短语在新的向量空间中表示形式会十分相似。
- 在确定向量表示时,Text embedding可以考虑单词的顺序。例如,短语“明天”可以被映射为与“天明”非常不同的向量。
- Text embedding通常适用于短文本。
应用场景
Elasticsearch支持词向量搜索能够在很多场景下进行应用,这里进行列举一些简单的应用,有些并不是当前场景下的最佳选择。
- QA:用户输入一段描述,给出最佳匹配的答案。传统基于关键字搜索问答的局限性之一在于用户必须了解一些特殊的名词,假如关键字没有匹配上则没有返回结果。而在使用词向量之后,直接输入类似的描述性语言可以获得最佳匹配的答案。
- 文章搜索:有时候只记得一篇文章在表达什么意思,而忘记了文章标题和关键字。这时候只需要输入自己记得的大致意思和记得句子,即可根据描述中隐藏的语义信息搜索到最佳匹配的文章。
- 图片搜索:这里的图片搜索有两种含义,一种是讲图片中的特征值进行提取生成向量,实现以图搜图模式的搜索。另一种是基于图片tag的方式,将tag进行向量化,这样可以搜索到语义相近的tag的图片,而不必完全相等。这两种方式在ES的词向量搜索中都可以支持。
- 社交网络:社交网络中的人都是一个单词,而其关注和粉丝都是和其相关的单词,因此可以每一个人的关注和粉丝形成一段“文本”去训练模型。想计算两个人是否相似或者两个的距离,只需要计算两个人的向量即可。
Elasticsearch的词向量搜索可以理解为提供了一个计算平台,而具体的应用场景需要自己评估是否适合。具体的效果好坏,其实还是取决于本身的模型训练质量和模型使用方式。
最佳实践
本例子以医疗领域的“智能问诊”为例进行了一个展示。在此说明这里仅仅是一个demo,重点介绍具体场景里如何使用Elasticsearch的向量搜索,其模型是否有更适合的或者效果是否满足用户使用在不做过多讨论。
预期功能
用户A生病了,在demo中输入一段症状描述,demo返回给用户得了什么病。
数据准备
demo需要准备的数据主要有两个:
- 用以训练模型的文本数据(下方流程图的Texts):这是大量的和医疗相关的文本,可以是从维基百科爬取的整篇整篇的文章,或者免费版权的医学杂志、网站等获得的文本段落。该数据只要和医疗相关即可,格式为一行一个段落,如下:
xxxxx一行医学相关的文本,百姓所说的感冒是指“普通感冒”,又称“伤风”、急性鼻炎或上呼吸道感染。感冒是一种常见的急性上呼吸道病毒性感染性疾病,多由鼻病毒、副流感病毒、呼吸道合胞病毒、埃可病毒、柯萨奇病毒、冠状病毒、腺病毒等引起。临床表现为鼻塞、喷嚏、流涕、发热、咳嗽、头痛等,多呈自限性。大多散发,冬春季节多发,但不会出现大流行。
一行医学相关的文本xxxxx
一行医学相关的文本xxxxx- 专业的疾病描述文本数据(下方流程图的Data):比如“感冒:伴随有发烧、流鼻涕、浑身无尽...”,该数据用以和用户的输入进行匹配,返回给用户最相关的疾病。数据格式为json,其最重要的为具体的症状描述一栏,如下:
[
{
"id": "1",
"name": "肝功能异常",
"department": "消化科",
"feature": "消化功能xxxxxxxxxxxxxxxxxxxxxxx\n"
},
{
"id": "2",
"name": "反胃",
"department": "消化科",
"feature": "xxxxxxxxxxxxxx为主要表现。\n"
}
]- 停用词表:分词时候去除停用词的。数据格式为一行一行的单个单词,如下:
两者
个
个别
临
为
为了
为什么由于数据涉及到隐私,这里不进行提供,仅仅在源码中提供了数据的格式,方便跑通程序。
流程及代码实现
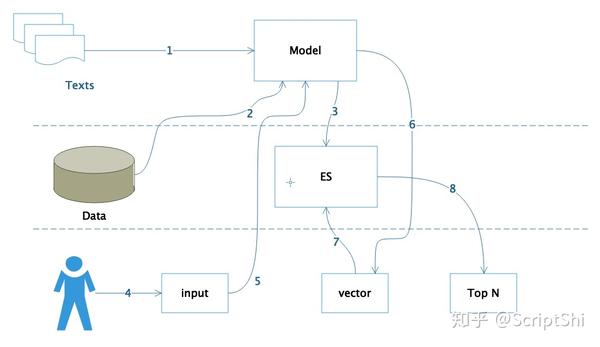

1:离线模型训练
这里将收集到的数据进行离线的顺联,生成 Doc2Vec 模型。离线训练模型特别花费时间,特别是在没有GPU的服务器上。该模型离线训练好后,后续会一直使用。
# 停用词
stopwords = [line.strip() for line in open('./data/ChineseStopWords.txt', encoding='UTF-8').readlines()]
def segment(sentence: str):
"""
结巴分词,并去除停用词
"""
resp = []
sentence_depart = jieba.cut(sentence.strip())
for word in sentence_depart:
if word not in stopwords:
if word != "":
resp.append(word)
return resp
def read_corpus(f_name):
"""
读数据
"""
with open(f_name, encoding="utf-8") as f:
for i, line in enumerate(f):
yield gensim.models.doc2vec.TaggedDocument(segment(line), [i])
def train():
"""
训练 Doc2Vec 模型
"""
train_file = "./data/train_data.txt"
train_corpus = list(read_corpus(train_file))
model = gensim.models.doc2vec.Doc2Vec(vector_size=300, min_count=2, epochs=10)
print(len(train_corpus))
model.build_vocab(train_corpus)
model.train(train_corpus, total_examples=model.corpus_count, epochs=model.epochs)
model.save("doc2vec.model")2~3:特征数据转化为向量,并存到ES中
从数据库中将我们标注好的疾病描述的数据拿出来,利用之前训练的模型,将每一个疾病的描述转化为向量,然后存在ES中。该向量具有表达一个疾病的含义,其是对疾病描述的embedding,在后续匹配过程中,只需要将用户输入的向量和ES中的向量进行匹配,即可找到最相关的向量。
因此,这一步,也是一个离线的过程,其包括:
- ES中使用指定的mapping创建索引。这里需要将向量这个Field“feature_vector”的类型设置为“dense_vector”,由于我们在model训练期间设置的纬度是300,这里需要指定dims为300.
def create_index():
print("begin create index")
setting = {
"settings": {
"number_of_replicas": 0,
"number_of_shards": 2
},
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"department": {
"type": "keyword"
},
"feature": {
"type": "text"
},
"feature_vector": {
"type": "dense_vector",
"dims": 300
}
}
}
}
get_es_client().indices.create(index=indexName, body=setting)
print("end create index")2. 将文本数据转化为向量
def embed_text(sentences):
"""
将所有的句子转化为向量
"""
model = doc2vec.Doc2Vec.load("doc2vec.model")
resp = []
for s in sentences:
resp.append(model.infer_vector(segment(s)).tolist())
return resp3. 将元数据和向量一起索引到es中
def bulk_index_data():
"""
将数据索引到es中,且其中包含描述的特征向量字段
"""
print("begin embed index data to vector")
with open("./data/data.json") as file:
load_dict = json.load(file)
features = [doc["feature"] for doc in load_dict]
print("number of lines to embed:", len(features))
features_vectors = embed_text(features)
print("begin index data to es")
requests = []
for i, doc in enumerate(load_dict):
request = {'_op_type': 'index', # 操作 index update create delete
'_index': indexName, # index
'_id': doc["id"],
'_source':
{
'name': doc["name"],
'department': doc["department"],
'feature': doc["feature"],
'feature_vector': features_vectors[i],
}
}
requests.append(request)
bulk(get_es_client(), requests)
print("end index data to es")4~8:用户输入症状表现,并转化为向量,从ES中搜索最相关的TopN个疾病
用户输入,我们假设从命令行输入即可。转化为向量也是使用最初训练的model进行了embed text,函数为上一个步骤使用过的embed_text。当用户的症状描述转化为一个向量时候,这时候即可从Es中进行搜索即可,在搜索的时候,需要使用Es的script_score的query,在query的scrip脚本中,将用户的向量放到查询语句的参数中,即可进行搜索,这里的搜索不是简单的文本匹配了,而是进行了语义层面的搜索。搜索结果中,我们将用户最大可能患有的疾病进行输出即可。
def test():
model = doc2vec.Doc2Vec.load("doc2vec.model")
es = get_es_client()
while True:
try:
query = input("Enter query: ")
input_vector = model.infer_vector(segment(query)).tolist()
resp = es.search(index=indexName, body={
"_source": ["name", "feature"],
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.queryVector, doc['feature_vector'])+1",
"params": {
"queryVector": input_vector
}
}
}
}
})
print("可能获得的疾病是:", end=" ")
for hit in resp["hits"]["hits"]:
print(hit["_source"]["name"], end="\t")
print("\n")
except KeyboardInterrupt:
return
效果
Enter query: 我眼睛充血,怎么办?
可能获得的疾病是: 红眼病 眼角膜发炎 外伤
Enter query: 呼吸不畅,咳嗽,胸闷是怎么回事?
可能获得的疾病是: 肺炎 上呼吸道感染 支气管炎总结
Text embedding 技术提供了一种捕获一段文本语义层信息的强大方法。通过基于embedding技术,我们可以超出传统单词级相似性概念,而使用文本语义层的信息对文档进行排名。
Elasticsearch仅仅是提供了一个计算平台,想要更好的使用词向量搜索,需要训练出适合应用场景的模型,具体是使用word embedding还是sentence embedding需要根据场景来具体选择,而通常情况下sentence embedding更加难以训练。
