To RegEx or Not To RegEx? (Part II)
A comprehensive tutorial on regular expression and how to use the re module to enhance its capabilities in Python

As my fellow cohort members and I navigate through the remaining content portion before embarking on our capstone project, we have been invited to a feast to fill our gluttonous bellies with the cornucopia of the topics left in the curriculum, which includes unsupervised learning algorithms, i.e., cluster and principal component analysis, neural networks, as well as concepts such as time-series, recommendation systems, and Big Data. Just a few easy-breezy concepts in data science…(in a very sarcastic tone).
This past weekend, I was listening to the news and was saddened by the surge of hate crimes against Asian-Americans, especially the elderly, here in the United States as a result of COVID-19-related anti-Asian rhetoric, initiated under the previous administration with terms like “Chinese Flu” or “Kung Flu”. Hearing these victims’ stories motivated me to focus on working with Twitter API and hate crime data in the scope of bias against the Asian-American community. I wanted to provide some context why I chose NLP and the preprocessing of Twitter data for the scope of RegEx use.
In the last blog, Part I of the series, we reviewed all the basics of regular expression with a focus on the language itself and the syntax, which is common to different programming languages. Here is a quick review of the characters or meta-characters you should be familiar with before we dive into the re module functions and methods:

Remember that everything inside a bracket refers to a single character, and quantifiers always follow the metacharacters, i.e. [0–9]* or [^AEIOU]{3}, which translates into “zero or more digits” or “exactly 3 non-vowels”. Lastly, the parentheses can be a capturing group or a more generalized grouping.
The Re Module
To unleash the full potential of the functionality of regular expressions in Python, we have to understand the matching operations that the module offers. Let’s go ahead and formally introduce the functions:
re.match(regex, string)

The match() function searches through the string string looking for the first instance of a match with the regex pattern. It produces a match object, which has the attribute group(). If you call match.group[1], the value in the first capturing group will be returned.
match is useful for extracting values within strings from your DataFrame. It is very similar to pd.str.extract(), except you can extract more than one piece of information from a particular string through capturing groups. For example, if you were interested in extracting the year, month, and date from a column in your dataframe, that can easily be done by re.match().
re.sub(regex, repl, string)

The sub() function searches through the string string looking for the first instance of a match with the regex pattern provided. sub() is useful for replacing or removing values from your dataframe. There is little discernable difference between sub() and pd.str.replace().
repl is what you intend to replace the string with when a match is made with the pattern regex. So if you want to remove rather than swap some string pattern into each value of a column, you can set repl to r'' (aka nospace), which effectively removes the pattern you matched.
sub is useful for substituting or removing a particular substring from each value in a DataFrame column. str.replace can perform the same function.
df.column = df.column.apply(lambda x: re.sub(r'pattern', "", str(x))re.findall(regex, string)

The findall function searches through the string string to find all the instances of a match with the regex pattern. It returns a list that you can assign any variable, let’s call itmatches, and the capturing groups aka parentheses (if they are more than one) are placed into a tuple of the size corresponding to the number of capturing groups. So when you iterate through an entire column, each row would produce a tuple corresponding to the matched capturing groups, and the rows would be appended to the list matchesas tuples.
findall() is especially useful in extracting more than one instance of a particular pattern or different parts of a string through capturing groups into a new column, i.e. producing a new column with all the hashtags or mentions from the Twitter API data.
There are other methods in the re module, but for general Machine Learning purposes, those are the most pertinent ones you need to know.
Application with Twitter Dataset
Twitter is a popular platform for Machine Learning enthusiasts to find datasets through API calling to fine-tune their skills in Natural Language Processing, sentiment analysis, and social network analysis. In the interest of time, I forked the Github repository of congressional tweets to apply the concepts immediately to some practice and to practice working through the steps of preprocessing.
For the full Jupyter notebook, please visit my repository and the notebook RegEx.ipynb :
We start by importing the modules and the Twitter data into a DataFrame:
# import modules
import json
import pandas as pd
import re
import regex
from datetime import datetime
pd.set_option(“display.max_rows”, 999)
pd.set_option(“display.max_columns”, 999)# import twitter data
data_json = open(‘data/tweets/2017–12–01.json’, mode=’r’).read()
df = pd.read_json(‘data/tweets/2017–12–01.json’)
df.head()
Here is a snapshot of the expanded view of the first 10 rows of the Twitter text:

An initial survey of the data indicates that we have to remove the callouts (@), hashtags (#), URL links (https://), character references (&), extraneous whitespaces, punctuations, the Twitter codes RT and QT, and numbers or number-related words before the tokenizing process.
I did not address contractions in this exercise, and you can remove rather than extract the hashtags and callouts depending on the needs of the project. I made decisions in the scope of illustrating the different functionalities of the re module.
Let’s work through the code in the scope of discussing the functions for each preprocessing step:
1. Removal of #Hashtag, @Callouts, and &Character References
Generally, when I want to extract a substring, I use re.findall(), but if I want to replace or more specifically to remove, I use re.sub.
I would like to talk about the expression \S (not a whitespace) for a moment because it is useful for including everything up until the end of the string. It can include numbers, letters, special characters, basically anything other than whitespace. Very handy.
2. Emoji Conversion and URL Link Removal
Here is an instance of where I am actually replacing using re.subrather than removing if you look in the code for Emojis. If you wanted to include the emojis in your sentiment analysis, you would need to convert the emojis into words. While I didn’t use the code, it provides an instance of replacing rather than removing.
Another point of discussion or content clarification is the capturing groups in the RegEx pattern in the code to remove URL links:
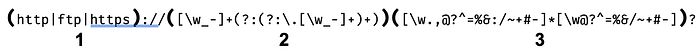
There are 3 capturing groups, and we can refer them with the indices 1, 2, and 3, not 0, 1, and 2 because it is not zero-indexed.
3. Punctuation and Digit Removal
Here we have the code for removing punctuations and numbers or number-related strings:
We have incorporated some string methods from Python, i.e. join and split, so you will need familiarity with string methods.
You don’t want to remove punctuations until you have taken care of your hashtags, mentions, character references, URL links, contractions, etc. When we removed the URL links earlier, because we used capturing groups, some of the punctuations were left behind, and this is where it gets removed.
4. Removing Extraneous Whitespaces
Here is the code for removing whitespaces:
Once all the characters have been cleaned up into lowercase words, the whitespaces need to be trimmed between words and in the very beginning and end of the entire string value.
5. Working with Time
I am giving a plug for the updated regex module. As I mentioned earlier, re.match will return a list of the matches, but what is cool about regex.matchis the option of returning your capturing groups and matches in a dictionary properly labelled:
regex.match(r’^...(?P<name1>regex1)...(?P<name2regex2)...(?P<name3>regex3)...$’, string)Here we have 3 capturing groups named year, month, day, which will become the corresponding keys and the capturing group value will become the corresponding value in a key:value pair of a nested dictionary, which is called by the groupdict() method:
# Extract year, month, day, and time into a dictionary
df[‘time’] = [x for x in df.time.apply(lambda x: regex.match(r’^(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})T(?P<time>\d{2}:\d{2}:\d{2})-\d{2}:\d{2}$’, str(x)))]
df.match = df.match.apply(lambda x: x.groupdict())# Convert into datetime ISO format
format = “%Y-%m-%dT%H:%M:%S%z”
df[‘datetime’] = df.time.apply(lambda x: datetime.strptime(x, format))
So I have covered how you will use the three main functions of the re module. If you are so motivated, you can learn about the regex module that offers some cool new functionalities.
Check out the following resources I found useful in my learning journey for RegEx:
- Coming soon….
More content at plainenglish.io

